
With Big Data comes big risks & the pain of handling the risks, hence we bring to you our comprehensive pain-relief guide to combat Big Data challenges for bigger victories.
The word “Big” in Big Data is not even that big at the level the data is being generated. The volume, velocity and variety of data – which is being curated and stored have overwhelmed the capabilities of infrastructure and analytics we have today. We are experiencing Moore’s law for data growth: data is doubling every 18 months.
According to IDC’s predictions – worldwide data will grow 61% to 175 zettabytes, with as much of the data residing in the cloud as in data centres. And that is almost 10 times the data, generated in 2016.
Data scientists have to simultaneously combine the data from multiple sources with different volume, variety and velocity – to gain useful insights that will turn into different demands on processing power, storage and network performance, latencies, etc.
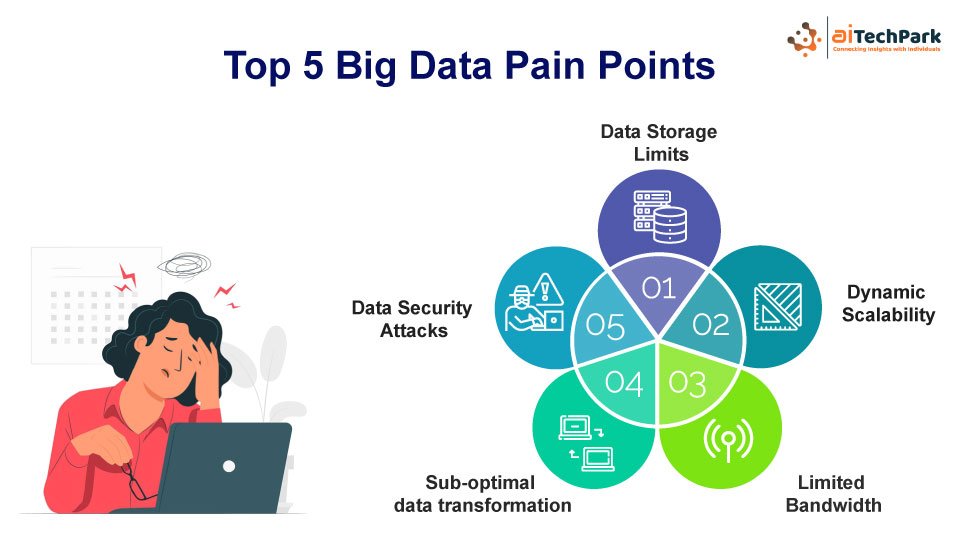
Top 5 Pain Points and Solutions for Big Data Infrastructure:
- Storage Media
Disk Input/output bottlenecks are one common source of delays in data processing. And there are few tricks which can help in minimizing the impact. And the solution to the same can be by upgrading your data infrastructure solid-state disks (SSDs) – that runs faster. Second option in-memory data processing – which is faster than relying on conventional storage.
- Scalability
If the data infrastructure can’t increase in size as the data grows, then it will undercut your ability to turn data into value. And on the other hand you wouldn’t want to maintain substantially more big data infra then the one you need. Otherwise it would be something like you are paying rent for the apartment you are not living in.
One of the solutions for the same is to deploy big data workloads in the cloud, where you can increase/decrease the size of your infrastructure virtually instantaneously according to your need. If you don’t want to shift all of your big data workloads to the cloud, you can consider keeping most of the workloads on premise and spillover can be handled by the cloud infrastructure.
- Network Connectivity
Things can go wrong due to multiple reasons. And here are the most common problems you might experience – that delay or prevent you from transforming big data into value.
One of the solutions is by paying for more and better bandwidth. A better approach is to architect your big data infrastructure in a way that minimizes the amount of data transfer – which needs to occur over the network. For instance, using cloud-based analytics tools to analyse data that is collected in the cloud, rather than downloading the data to an on premise location first.
- Sub-optimal data transformation
Usually applications structure the data in a way that works best for them, with little consideration of how well those structures would work for other applications or contexts. The reason data transformation is quite important. It will let you convert data from one format to another. And if done incorrectly – data transformation can quickly cause more trouble than it is worth. And if you automate the data transformation and ensure the quality of the resulting data, you maximize your data infrastructure’s ability to meet your big data needs, no matter how your infrastructure is constructed.
- Data Security
As we all know, with big data comes big risks. Big data inputs come in from multiple sources – it is important to ensure that all the data which comes in are secured. Trojans that slip in can subvert the entire system. It is quite easy to manipulate Big Data at the processing level, as the Big Data processing tools are not designed with such high-end security in mind.
Plus, big data processing takes place in the cloud, and all the inherent security risks of data theft as data moves back and forth between the company servers to the cloud server are ever present. There are severe limitations on the available authentication solutions, too.
For example, basic authentication and authorization require two completely different stacks that incompletely support various sections of Hadoop but not the others.